本文参考了Redis源码3.0分支和《Redis设计与实现》。
对象
Redis基于下面提到的底层数据结构创建了一个对象系统,这个系统包括String、List、Set、Hash、Sorted Set这五种对象,每种对象都用到了至少一种底层数据结构。Redis中的每个对象都由一个redisObject结构表示,该结构中和保存数据有关的三个属性分别是type、encoding和ptr。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27/* Object types */
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;
底层数据结构
SDS - Simple Dynamic String
SDS是二进制安全的。
定义
1 | typedef char *sds; |
API
1 | /* Append the specified binary-safe string pointed by 't' of 'len' bytes to the |
List
就是大家都学过的链表,方法名也大多顾名思义。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54/* Node, List, and Iterator are the only data structures used currently. */
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
/* Functions implemented as macros */
/* Prototypes */
list *listCreate(void);
void listRelease(list *list);
list *listAddNodeHead(list *list, void *value);
list *listAddNodeTail(list *list, void *value);
list *listInsertNode(list *list, listNode *old_node, void *value, int after);
void listDelNode(list *list, listNode *node);
listIter *listGetIterator(list *list, int direction);
listNode *listNext(listIter *iter);
void listReleaseIterator(listIter *iter);
list *listDup(list *orig);
listNode *listSearchKey(list *list, void *key);
listNode *listIndex(list *list, long index);
void listRewind(list *list, listIter *li);
void listRewindTail(list *list, listIter *li);
void listRotate(list *list);
Dict
Dict的核心就是Separate Chaining Hash Table。 随着操作的不断进行,哈希表保存的键值对会逐渐地增多或减少,为了让哈希表的负载因子(USED/BUCKETS)维持在一个合理的范围之内,当哈希表保存的键值对数量太多或太少时,程序需要对哈希表的大小进行相应的扩展或收缩。
定义
1 | typedef struct dictEntry { |
核心方法实现
1 | /* Add an element to the target hash table */ |
Skiplist
跳跃表是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。 跳跃表支持平均O(logN)、最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。跳跃表的实现比平衡树更简单。
1 | /* ZSETs use a specialized version of Skiplists */ |
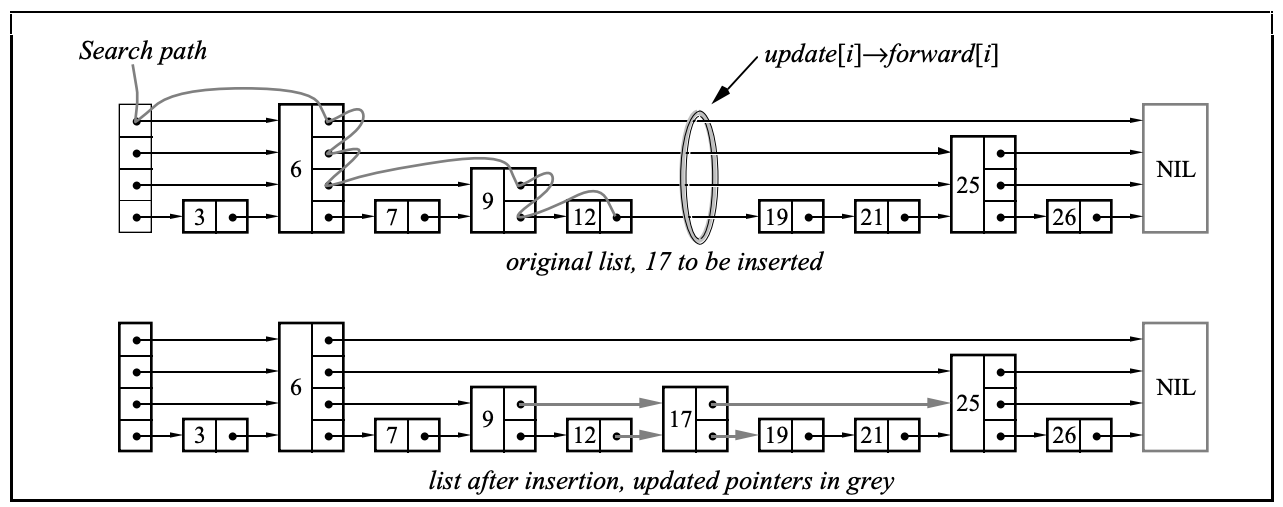
插入时的核心逻辑:
- 找到插入的位置
- 随机得到新插入节点的level
- 处理为了插入当前节点穿过的指针和未穿过的指针的指向和跨度
删除时的核心逻辑:
- 找到删除的位置
- 处理要删除的节点穿过的指针和未穿过的指针的指向和跨度
- 如果可以,减小跳跃表的level
下面这个题可以使用平衡树来解,这里为了练习使用跳跃表,注意根据题意特殊处理。 SPOJ ORDERSET
其他底层数据结构
其他底层数据结构还包括了压缩列表(Ziplist)和整数集合(Intset)等。
对象的实现
Redis对象通过encoding属性来设定对象所使用的编码,而不是为特定类型的对象关联一种特定的编码。Redis可以根据不同的使用场景来为一个对象设置不同的编码,从而优化对象在某一场景下的效率。Redis对象还会根据不同的条件,从一种编码转换成另一种编码。
不同类型和编码的对象:
| 类型 | 编码 | 对象 |
|---|---|---|
| REDIS_STRING | REDIS_ENCODING_INT | 使用整数值实现的字符串对象 |
| REDIS_STRING | REDIS_ENCODING_EMBSTR | 使用 embstr 编码的简单动态字符串实现的字符串对象 |
| REDIS_STRING | REDIS_ENCODING_RAW | 使用简单动态字符串实现的字符串对象 |
| REDIS_LIST | REDIS_ENCODING_ZIPLIST | 使用压缩列表实现的列表对象 |
| REDIS_LIST | REDIS_ENCODING_LINKEDLIST | 使用双端链表实现的列表对象 |
| REDIS_HASH | REDIS_ENCODING_ZIPLIST | 使用压缩列表实现的哈希对象 |
| REDIS_HASH | REDIS_ENCODING_HT | 使用字典实现的哈希对象 |
| REDIS_SET | REDIS_ENCODING_INTSET | 使用整数集合实现的集合对象 |
| REDIS_SET | REDIS_ENCODING_HT | 使用字典实现的集合对象 |
| REDIS_ZSET | REDIS_ENCODING_ZIPLIST | 使用压缩列表实现的有序集合对象 |
| REDIS_ZSET | REDIS_ENCODING_SKIPLIST | 使用跳跃表和字典实现的有序集合对象 |
Set
Set的编码可以是intset或hashtable。 hashtable编码的集合对象使用字典作为底层实现,字典的每个键都是字符串对象,字典的值则全部为NULL。
Sorted Set
https://news.ycombinator.com/item?id=1171423 Sorted Set的编码可以是ziplist或skiplist。 1
2
3
4typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;skiplist时,redisObject.ptr指向zset类型。 skiplist本身不支持通过key查value,zset使用dict字典为有序集合维护了一个从成员到分值的映射。